This page hosts the accepted artifact for our OOPSLA 2018 paper on SymPro:
Artifact
- Paper (PDF, 829 kB)
- VirtualBox image (OVA, 1.7 GB)
Artifact overview
We have provided a VirtualBox image, containing:
- Two prototype implementations of symbolic profiling – one for Rosette, and one for Jalangi.
- Benchmarks and case studies for both implementations, corresponding to Sections 5 and 6 of the paper.
After installing VirtualBox, import our VirtualBox image (File > Import Appliance).
When booted, the virtual machine will log in automatically,
open a terminal,
and open a copy of this instruction page.
The virtual machine user is artifact with password artifact.
Note that the virtual machine requires at least 6 GB of RAM for all benchmarks to pass.
Directory layout
The artifact user’s home directory contains the following directories:
symproholds a fork of Rosette with our prototype symbolic profiler. This version of Rosette is already installed via Racket’s package manager.benchmarksholds our Rosette case studies and benchmarks, together with a runner scriptrun.pyfor invoking them.user-studyholds the materials from our user study (Section 6.3).jalangiholds a fork of Jalangi with our prototype symbolic profiler, together with Jalangi’s built-in benchmark suite.examplesholds various example Rosette programs used in the paper.instructionsholds these instructions.
Getting started
From a terminal inside the virtual machine, run the following command (from the home directory):
$ raco symprofile -m slow sympro/test/profile/ferrite/rename.rkt
This command invokes the Rosette symbolic profiler on the (unrepaired) Ferrite case study from Section 5.1 of the paper. It should take about 20–30 seconds, and when finished, open a browser window with output similar to this:
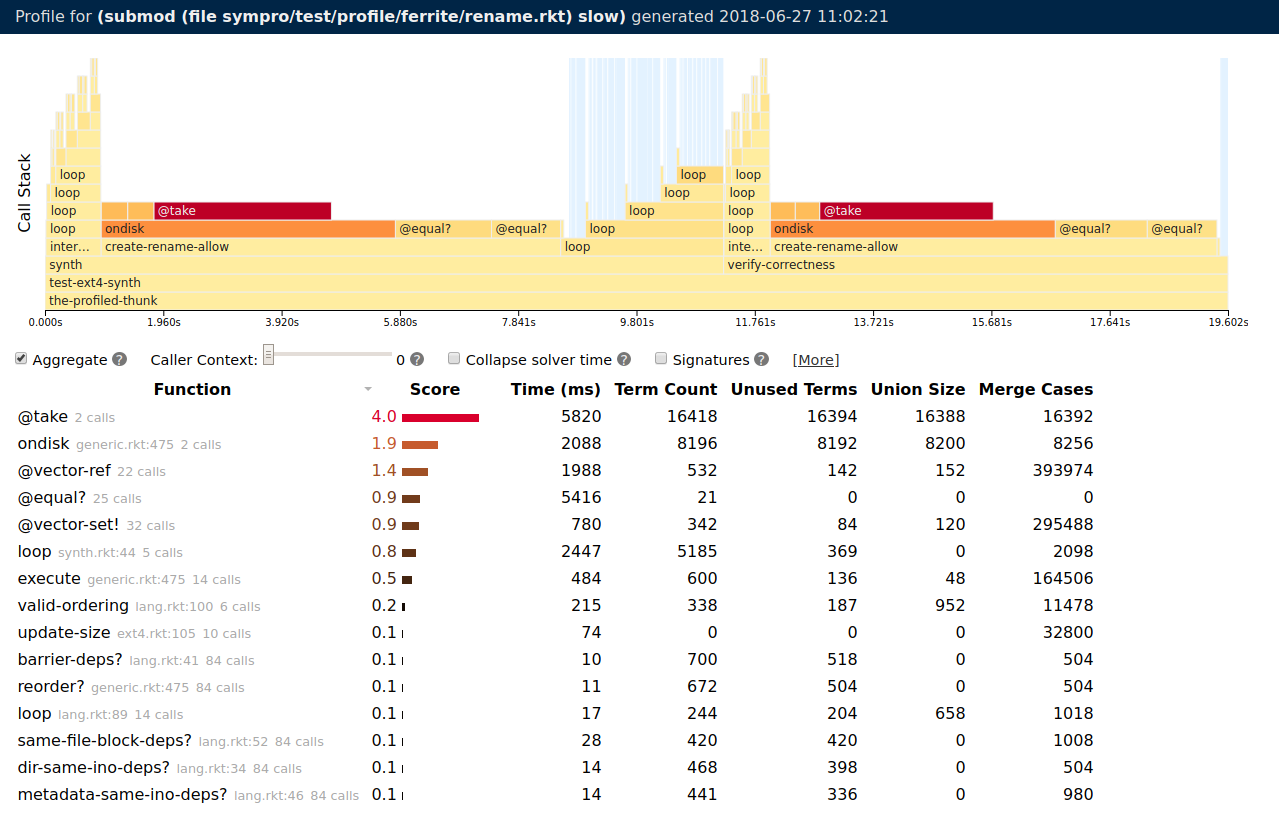
The chart at the top visualizes the evolution of the call stack over time. The table at the bottom lists the functions called by the program, ranked by a score computed from the other columns of data. The five columns of data quantify the effect of a function on symbolic evaluation:
- Time is the exclusive wall-clock time spent in a call
- Term Count is the number of symbolic values created during a call
- Unused Terms is the number of those symbolic values that do not appear in queries sent to the solver
- Union Size is the sum of the out-degrees of all nodes added to the evaluation graph (i.e., how many times symbolic evaluation forked)
- Merge Count is the sum of the in-degrees of all nodes added to the evaluation graph (i.e., how many times symbolic evaluation merged)
If this step succeeds, the artifact is ready for use.
Step-by-step guide
The artifact addresses all claims from the evaluation sections of the paper (Sections 5 and 6). In particular, we include the unrepaired and repaired versions of each case study in Section 5, and scripts to reproduce the results in Section 6.
Case studies (Section 5)
The artifact provides a script, benchmarks/run_cs.py,
to reproduce the results for the case studies in Section 5.
To run all the case studies (except Cosette, see below)
and get results to compare to Table 2,
run (from the home directory):
$ python benchmarks/run_cs.py -- all
This script will run each case study benchmark twice: once without our repair, and once with the repair. For each run, the script will report the time taken with and without the repair, and the speedup for the repaired version. The total time to reproduce all six case studies by running this script is about 20 minutes.
Generating profiles.
The same script can also be used to invoke the symbolic profiler
on the six case study benchmarks
(in order to inspect the profiles of the unrepaired programs
that gudied us to the repairs).
To do so, pass the -p flag to run_cs.py:
$ python benchmarks/run_cs.py -p -- all -bonsai -neutrons
With this flag enabled, each case study will run only the unrepaired version. After each run, the output from the symbolic profiler will be opened in a browser tab for inspection. This command takes about 15 minutes. This command excludes the Bonsai and Neutrons benchmarks, because their profiles are very resource intensive to load and display in the browser. To inspect them separately, run (e.g.):
$ python benchmarks/run_cs.py -p bonsai
Experimenting manually.
Each of the case studies resides in a subfolder of the benchmarks folder.
In each subfolder is a Git repository with two branches:
master contains the unrepaired source code,
while repaired contains the repaired source code.
To experiment manually with a benchmark,
go to its subdirectory and check out either the master or repaired
branch (i.e., git checkout master or git checkout repaired).
Then invoke the benchmark using the corresponding command below
(from within the benchmark’s directory):
| Benchmark | Command |
|---|---|
bonsai |
racket nanoscala.rkt |
ferrite |
racket chrome.rkt |
fluidics |
racket ex2.rkt |
neutrons |
racket filterWedgeProp.rkt |
quivela |
racket test-inc-arg.rkt |
rtr |
racket benchmarks/matrix/translated0.rkt |
To invoke the symbolic profiler on these benchmarks,
replace racket with raco symprofile in the commands above.
To see the code changes between the original and repaired version of a benchmark, run this command from within a benchmark’s directory:
$ git diff master repaired
Cosette case study
Unlike the other case studies, the unrepaired version of the Cosette benchmark does not terminate within an hour (as noted in the paper), so the automated scripts above do not test Cosette.
To test Cosette manually, first enter the benchmarks/cosette directory,
and then run:
$ git checkout master
$ raco symprofile --stream rosette/cidr-benchmarks/oracle-12c-bug.rkt
A browser window will open, and the output of the symbolic profiler will stream to the browser as the Cosette benchmark runs. This benchmark won’t terminate, so after seeing the general trend of the profile output (which takes about a minute), kill the running command in the terminal (i.e., CTRL+C) and close the browser.
To see the performance of the repaired version, run:
$ git checkout repaired
$ racket rosette/cidr-benchmarks/oracle-12c-bug.rkt
This version should terminate in about 10 seconds.
Note that in the paper, we report the effect of two optimizations
separately, but the repaired branch combines both optimizations.
Evaluation (Section 6)
The evaluation in Section 6 of the paper addresses four research questions:
- Is the overhead of symbolic profiling reasonable for development use?
- Is the data collected by SymPro necessary for correctly identifying bottlenecks?
- Are programmers more effective at identifying bottlenecks with SymPro?
- Is SymPro effective at profiling different symbolic evaluation engines?
The artifact contains material to reproduce our results for all four questions.
Is the overhead of symbolic profiling reasonable for development use? (Section 6.1)
To show that the overhead of symbolic profiling is reasonable,
we measure the profiling overhead on the suite of 15 benchmarks in Table 1.
The artifact provides a script, benchmarks/run.py,
to reproduce the results from this table.
To run all the benchmarks and reproduce the results from Table 1
(takes about 12 hours!, see below for a smaller version), run:
$ python benchmarks/run.py all
For each benchmark, this script will generate output similar to:
=== wallingford ===
type,time,real,memory
profile,6.685,29.52,1170148.0
baseline,5.106,18.0,618008.0
profile,6.513,28.26,1171964.0
baseline,5.356,18.27,621980.0
profile,6.74,29.03,1171308.0
baseline,5.106,17.8,619640.0
profile,6.531,28.41,1171728.0
baseline,5.176,17.89,619780.0
profile,6.573,28.41,1169784.0
baseline,5.115,17.71,619120.0
mean,1.2784 [1.2269, 1.3300],1.6020 [1.5558, 1.6481],1.8896 [1.8854, 1.8937]
geomean,1.2779 [1.2269, 1.3309],1.6016 [1.5559, 1.6487],1.8896 [1.8854, 1.8937]
Each benchmark is run five times both with and without the profiler. For each of these ten executions, the output shows:
time, the execution time in seconds of the benchmark (which is what we report in the paper)real, the end-to-end wall-clock time, which includes compilation and Racket startupmemory, the peak memory usage in MB
The final lines of output show the arithmetic and geometric means
of the overhead for each metric (i.e., baseline / profile),
together with 95% confidence intervals for those overheads.
In the paper, we report the geometric mean of time and memory overhead,
so those are the numbers to compare to Table 1. For example, for Wallingford,
the output above shows a 27.79% time overhead and 89.0% memory overhead,
compared to 6.8% and 90.4% reported in the paper.
We expect some variance in overhead results due to virtualization.
Running smaller experiments. Since the above experiment takes about 12 hours, the script also supports smaller versions. This version runs each benchmark only once, and excludes GreenThumb and Neutrons (which are slow and memory-intensive):
$ python benchmarks/run.py -n 1 -- all -greenthumb -neutrons
This version of the command takes about 35 minutes.
The script can also run individual benchmarks; for example, the Wallingford result above can be reproduced by running:
$ python benchmarks/run.py wallingford
The available benchmark names match those in the paper (except in lowercase),
and can be seen with the -h argument to benchmarks/run.py.
Is the data collected by SymPro necessary for correctly identifying bottlenecks? (Section 6.2)
To show the importance of the data symbolic profiler gathers, Table 2 performs a sensitivity analysis. For each benchmark with a known bottleneck, the table ranks the procedures in the benchmark using only subsets of the data gathered by the profiler. The results show that all the data gathered is necessary to correctly rank every bottleneck first (i.e., the “All” column ranks every bottneck 1, whereas other columns using subsets of the data rank some bottlenecks lower).
The artifact provides a script, benchmarks/run_sensitivity.py,
to reproduce the results of Table 2.
To run all the benchmarks (except Cosette, which has the same non-termination
problem as described above), run:
$ python benchmarks/run_sensitivity.py all
This command will take about 30 minutes.
For each benchmark, the script outputs data similar to:
=== MemSynth ===
looking for bottleneck named `loop`
Time: 8
Heap: 4
Graph: 1
All: 1
This output corresponds to the MemSynth row in Table 2. We expect some variation, particularly in the Time results, due to virtualization.
Are programmers more effective at identifying bottlenecks with SymPro? (Section 6.3)
Section 6.3 presents the results of a user study we conducted with Rosette programmers.
In the user-study directory,
the artifact contains both the tasks used for the study
and the raw quantitative data from the user study, as summarized in Figure 6 of the paper.
Figure 6 can be recreated by running (from the user-study directory):
$ Rscript results.R
The resulting figure is results.pdf and can be opened:
$ xdg-open results.pdf
Is SymPro effective at profiling different symbolic evaluation engines? (Section 6.4)
Section 6.4 shows that symbolic profiling is also effective for Jalangi,
which contains a symbolic execution engine for JavaScript.
In the jalangi directory,
the artifact contains a fork of Jalangi with symbolic profiling implemented,
together with a script run.py to reproduce the results in Section 6.4
To run the three benchmarks in Section 6.4, run (from the jalangi directory):
$ python run.py
This command takes about a minute. For each of the three benchmarks, this script generates output similar to:
=== rbTree ===
profile:
name,score,cases,terms,time
insertFixup,1.841045,2421,0,331.550603
compare,1.690497,633,372404,169.130987991
insert,1.622057,1506,0,394.212559
get_,0.714313,786,0,153.606320005
leftRotate,0.486498,763,0,67.5439909995
rightRotate,0.408571,589,0,65.1566099972
RBnode,0.066755,60,0,16.5459880028
contains,0.038201,40,0,8.54595200159
RedBlackMap,0.013571,25,0,1.278926
readInput,0.001204,0,5,0.469451999292
original: 5743.235806ms
repaired: 3097.30938s
speedup: 1.85426610693
This output first shows the symbolic profile of the red-black tree benchmark, which identifies the insert procedure as the bottleneck (entries in the profile are sorted by the symbolic profiler’s score). The unrepaired version of the benchmark runs in 5.7s, while the repaired version runs in 3.1s, for a total speedup of 85%. We expect some variance in the speedup results compared to the paper due to virtualization, especially in the BDD benchmark where the achieved speedup is small.
Reusability and experimenting further
We expect the Rosette symbolic profiler to be reusable (and it will soon be merged into Rosette).
Given a Rosette program program.rkt (i.e., a Racket program whose first line is #lang rosette),
running the following command will generate a profile of that program:
$ raco symprofile program.rkt
The artifact includes several programs to experiment with to demonstrate reusability.
The programs in the examples directory are those mentioned in the paper.
The user-study directory includes the tasks from the user study.
We expect the profiler to also work on other Rosette programs
(e.g., from the documentation) without issue.